Data Integration?
Data integration is the process of turning raw data into analytical models that can serve business purposes and help guide strategic decisions.
With effective data integration, you can extract data from a variety of sources, including production databases, cloud-based applications, real-time data feeds and online data streams and build a single source of truth.
The rise of the cloud means there is a huge volume, variety and velocity of data constantly being produced. However, raw data is usually not directly useful. It must be understood, cleaned, and turned into models that humans can consume, interpret and use to drive business decisions.
Why is Managed Data integration being efficient?
It’s much more efficient and timely to rely on managed data integration services. Full-service solutions are the simplest way to connect disparate data sources quickly and efficiently without diverting engineering resources, adding operational complexity to the IT stack, or introducing new data security and privacy risks. Managed services typically support hundreds of other data sources, making it easy to expand access to new and other commonly used internal data sources.
In most cases, data teams can make the connection within minutes and initiate the flow of data immediately. Within hours, stakeholders can start manipulating and analyzing data. And data engineers will be able to focus on high-value projects instead of maintaining data pipelines.
In short, most enterprises can rely on a managed data integration service for 80 or 90 percent of their needs, and then go the DIY route when necessary. This hybrid approach will allow them to take advantage of the efficiency and speed of a managed solution by automating what they can, without limiting future data integration options in any way.
How to integrate data: ETL vs. ELT?
The traditional approach to data integration, Extract-Transform-Load (ETL), dates from the 1970s and is so ubiquitous that “ETL” is often used interchangeably with data integration. Under ETL, data pipelines extract data from sources, transform data into data models for analysts to turn into reports and dashboards, and then load data into a data warehouse.
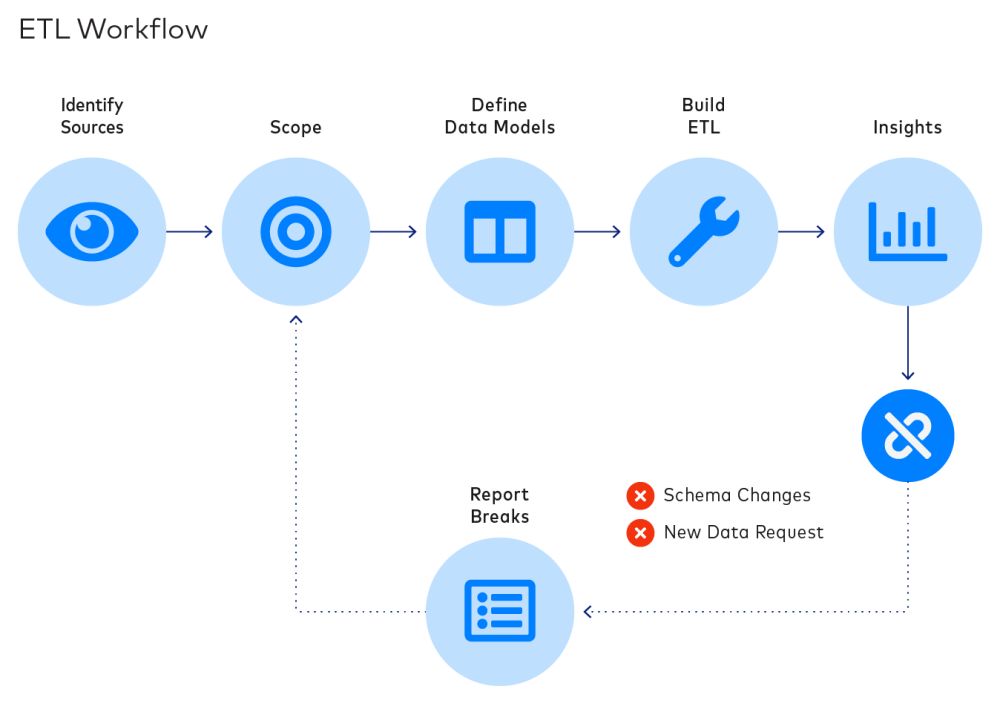
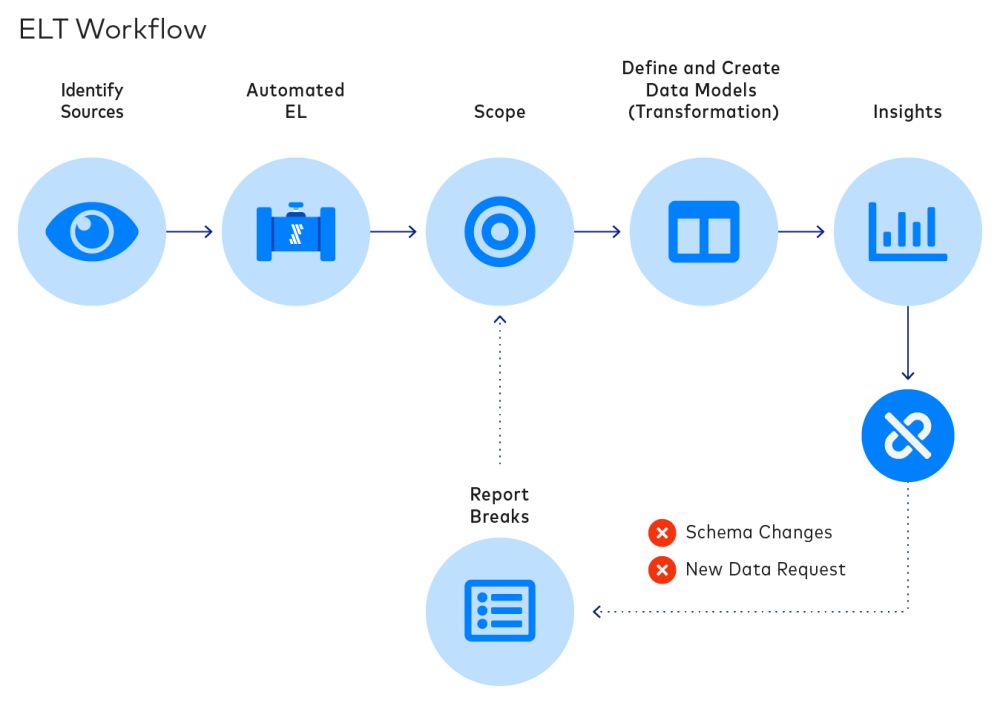
ELT? A modern alternative to ETL
The ability to store untransformed data in data warehouses enables a new data integration architecture, Extract-Load-Transform (ELT), in which data is immediately loaded to a destination upon extraction, and the transformation step is moved to the end of the workflow.
Data integration with the modern data stack
The modern data stack, in short, is a cloud-based data stack powered by automated data integration.
It is a suite of tools and technologies that includes the following:
- Data pipelines that combine data connectors with standardised schemas and a wide variety of transformations. These pipelines should be automated and constructed with no or low-code processes.
- Data warehouse that is secure, resilient and reliable and is based in the cloud so it can easily scale for additional compute and storage requirements.
- Data transformation tools to track data lineage, construct new data models and leverage off-the-shelf data models for well-known metrics.
- Business intelligence platforms that work well with the chosen data warehouse and offer automatic reporting, version control, collaboration, dashboards and data visualisations.
Fivetran is a highly comprehensive ELT tool, that helps you centralise the data from disparate sources which you can manage directly from your browser. Fivetran extracts your data and loads it into your data destination. Integrations include Applications, Files, Databases, Events, Destinations, and Functions.
With Fivetran, you can centralise all of your data into your data warehouse in just minutes through a simple cloud-based ELT data pipeline. We believe that your internal data is your most powerful asset and that true insights come from building an infrastructure that is rooted in your ability to leverage that same data. It just shouldn’t take months to do so.
Fivetran is the smartest way to replicate data into your warehouse. They’ve built the only zero-maintenance pipeline, turning months of ongoing development into a 5-minute setup. Their connectors bring data from applications and databases into one central location so that analysts can unlock profound insights about their business.
Centralise your data in minutes not months
intelia has partnered with Fivetran – a managed ELT service providing a seamless way to integrate multiple sources and sinks.
Connectivity to popular platforms including BigQuery, Snowflake, SQL Server, PostgreSQL & services like Salesforce & Zendesk out of the box, allows for data integration within minutes.
How can intelia help?
intelia & Fivetran Partnership
intelia is a Fivetran Delivery partner with consultants trained in delivering enterprise solutions across APAC. We believe Fivetran is a core part of the next generation data stack – allowing for the centralisation of data from disparate sources which you can manage directly from your browser.
Contact us for a no-obligation chat about Fivetran and our other data & analytics service offerings.
Core Concepts
The modern data stack, in short, is a cloud-based data stack powered by automated data integration.
It is a suite of tools and technologies that includes the following:
- Data pipelines that combine data connectors with standardised schemas and a wide variety of transformations. These pipelines should be automated and constructed with no or low-code processes.
- Data warehouse that is secure, resilient and reliable and is based in the cloud so it can easily scale for additional compute and storage requirements.
- Data transformation tools to track data lineage, construct new data models and leverage off-the-shelf data models for well-known metrics.
- Business intelligence platforms that work well with the chosen data warehouse and offer automatic reporting, version control, collaboration, dashboards and data visualisations.
Fivetran is a highly comprehensive ELT tool, that helps you centralise the data from disparate sources which you can manage directly from your browser. Fivetran extracts your data and loads it into your data destination. Integrations include Applications, Files, Databases, Events, Destinations, and Functions.
With Fivetran, you can centralise all of your data into your data warehouse in just minutes through a simple cloud-based ELT data pipeline. We believe that your internal data is your most powerful asset and that true insights come from building an infrastructure that is rooted in your ability to leverage that same data. It just shouldn’t take months to do so.
Fivetran is the smartest way to replicate data into your warehouse. They’ve built the only zero-maintenance pipeline, turning months of ongoing development into a 5-minute setup. Their connectors bring data from applications and databases into one central location so that analysts can unlock profound insights about their business.
The building blocks of data organisation are tables and schemas. You can think of a table as a file organised by rows and columns and of a schema as a folder that contains multiple tables. Each Fivetran connector creates and manages its own schema.
In simple terms, a Fivetran connector reaches out to your source, receives data from it, and writes it to your destination. Depending on the type of connector, Fivetran either collects data that the source pushes or sends a request to the source and then grabs the data that the source sends in response.

Shared responsibility model
Data transformation and modelling is a shared responsibility between Fivetran and you, the customer. This shared model relieves you of much of the data integration burden because Fivetran:
- designs, builds, operates and maintains the extract and load from the source system to the destination schema; and
- orchestrates the transformation, modelling, and validation within the destination.
Data types
- Fivetran supports a standard list of data types for all our destinations.
- Fivetran analyses the source data to check whether the connector has specified the data type for a column.
- Fivetran selects an appropriate data type for the data stored in that column before writing to your destination.
- Fivetran connectors generate both explicitly- and implicitly typed columns.
Transformations and mapping
Fivetran automatically maps internal source types to supported destination types.
There are a few types of transformations that Fivetran performs automatically before loading the data. The first type of transformation is minimal data cleaning.
- Transform data types that are not supported in the target destination.
- Perform a small amount of data manipulation and cleaning to put it in an optimal format to work within your destination.
- Perform a few schema transformations. Depending on how structured and well formatted the source data or API endpoints are, Fivetran performs some normalising and cleaning of the schema. Schema transformations happen on a connector by connector basis.
Architecture
Fivetran connects to all your supported data sources and loads the data from them into your destination. Each data source has one or more connectors that run as independent processes that persist for the duration of one update. A single Fivetran account, made up of multiple connectors, loads data from multiple data sources into one or more destinations.

Global Case Studies
Case Study 1
The Challenge
Nando’s built its success on providing customers with a great dining experience and wants to continue this mission by using data to better communicate with customers. The Engineering team is responsible for ensuring the infrastructure can support data-driven marketing strategies, particularly around customer loyalty and the rewards program.
The problem that they faced was that their existing infrastructure was not meeting the demands of the business.
“It was quite challenging, especially from a marketing point of view. They need fast access to reports and dashboards to help them run successful campaigns and action the data and we just didn’t have that flexibility” said Puig, Technical Lead.
“Whole databases had to be replicated every day and it was very hard to model,” said Puig. “Obviously, it was far from optimal. The team spent quite a lot of time building one of those pipelines and it went far from perfect.”
The Solution
The decision was taken to start from scratch and move the business’ data from SQL server to Google Cloud Platform. BigQuery was chosen as the data warehouse at the centre of a modern data stack; Fivetran was selected as the data source connector alongside Google Cloud Resources.
Fivetran was chosen over Stitch for data integration because of its flexibility, ease of use, and speed.
“We compared Fivetran and Stitch’s Stripe connector. We went with Fivetran because the volume-based pricing was more transparent, and for being close to our tech stack in GCP.” said Miguel Puig Garcia.
Results
The biggest benefit of the modern data stack is seeing how the business is performing on a granular level, from the most profitable restaurants to what customers are ordering. Fivetran pulls payment data from Stripe that feeds Looker dashboards, giving the business fast access to insights on everything from deals on meals to possible incidents of fraud.

Case Study 2
DOUGLAS is the leading premium beauty platform in Europe, inspiring customers to live their own kind of beauty. Offering more than 130,000 beauty and lifestyle products in online shops, the beauty marketplace, and over 2,000 stores.
The Challenge
Making eCommerce a business priority
To accomplish the paradigm shift to “Digital First”, DOUGLAS knew it needed to enhance its existing infrastructure and processes, particularly around BI (Business Intelligence) and data analytics.
Before Fivetran, scattered systems for collecting data and an overreliance on spreadsheets and manual input were not scalable.
The Solution
Selecting fit-for-purpose infrastructure
DOUGLAS made the decision to invest in a future-orientated, best-practice combination of Fivetran for automated data integration, Snowflake for the data warehouse, and Tableau for data analytics. Around 200 active connectors are pulling data from multiple data sources with Fivetran. This has given the business market intelligence across everything from assessing the most successful digital advertising campaigns to insights into product and pricing trends.
With automated data integration by Fivetran, BI analysts, BI engineers, data scientists, as well as marketing and eCommerce experts can turn data into actionable insights more quickly.
Results
The real game-changer was replacing manual processes with an automated environment. With the modern data stack, DOUGLAS calculates it saves the time equivalent to 2-3 full-time employees. The performance gains, in terms of fast access to data and the resilience and scalability of the new infrastructure, have given DOUGLAS a future-proof foundation for further growth. More sophisticated data analytics are already underway, with one workstream delving deeper into data science.
Contact us for a no-obligation chat about reducing your integration time using a managed service like Fivetran and how to supercharge your data journey using out other data & analytics service offerings.