Hosting A Text Embedding Model That is Better, Cheaper, and Faster Than OpenAI’s Solution
| @intelia | October 2

Embedding is a process that converts text into a vector representation. This vector representation captures the meaning of the text, and can be used for a variety of downstream tasks, such as classification, clustering, question answering, and information retrieval.
In the context of generative AI, embedding models play a critical role. This is because large language models (LLMs) have a limited context length. If we want to generate text that is longer than the context length limit of the LLM, we need to use an embedding model to process the text bite by bite.
Even though the maximum context length of LLMs is increasing (the newly released Claude 2 offers 100K tokens of context length, and researchers are discussing 1M tokens), it is still possible to cache the results of the embedding model in a vector store to avoid the repetitive costs of invoking the LLM. This architecture is known as Retrieval Augmented Generation (RAG).
Here is a case study of how RAG works:
Embedding models are essential for many LLM applications. Many LLM vendors have developed their own embedding models, and OpenAI is no exception. The OpenAI embedding model, text-embedding-ada-002, has been a popular choice for many people due to its association with ChatGPT. However, it is important to ask whether this is the best option for everyone.
Does text-embedding-ada-002 lead the race just like ChatGPT does? Moreover, even if the close-sourced embedding model does have cutting-edge performance, does the not-tuneable model fit our needs?
How to evaluate embedding models
Embedding model evaluation was originally project-specific, making it difficult to compare the performance of different models. To address this issue, generic benchmark systems were developed to provide a common ground for evaluating embedding models.
The two most popular benchmark systems are BeIR and MTEB. BeIR has 17 datasets and focuses on the information retrieval task, which is more relevant to the RAG application in the case study. MTEB, on the other hand, has 56 datasets and 8 tasks, including information retrieval.
BeIR is a good choice for evaluating embedding models for information retrieval tasks. It is a well-established benchmark system with a large number of datasets. However, it is not a good choice for evaluating embedding models for other tasks, such as classification or clustering.
MTEB is a more comprehensive benchmark system than BeIR. It has a wider range of datasets and tasks, making it a good choice for evaluating embedding models for a variety of tasks. However, it is not as well-established as BeIR, so there may be less data available for some of the tasks.
The existence of BEIR and MTEB made evaluating embedding models much easier. However, it doesn’t mean that project-specific benchmarks should be discarded. We need to use the benchmark as a guide rather than the Bible. There are many cases where the benchmark datasets don’t reflect the data features of the project. In that case, it may be plausible to develop your own evaluation dataset.
Having said that, how does the OpenAI embedding model perform in the benchmark? It’s the following:
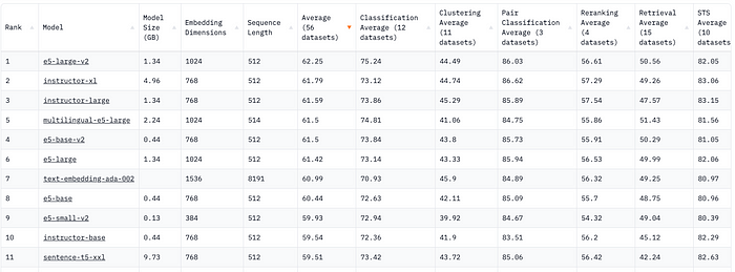
The OpenAI embedding model ranked 7th on the overall leaderboard. It is the best model for the clustering task and the 7th best model for the information retrieval task. Unfortunately, its performance for all other tasks is not impressive at all. Most of them are not even in the top 10.
On the contrary, you may have noticed the multiple occurrences of the E5-xx models. They are leading the race, and their lean size is eye-opening. The E5_large_v2 is only 1/3 of the instructor-x1; the E5-small-V2 is only 1% of the size of sentence-t5-xxl. The tiny E5-small-v2 outperformed the T5, despite the fact that it is a new model and was one of the best-performing models! That’s really significant. Let’s have a closer look at the E5 model.
Meeting E5
In the new paper Text Embeddings by Weakly-Supervised Contrastive Pre-training, a Microsoft research team has introduced a new text embedding model called Embeddings from Bidirectional Encoder Representations (E5). E5 is a general-purpose model that can be used for a variety of tasks, such as retrieval, clustering, and classification. It is the first model to surpass the BM25 baseline on the BEIR retrieval benchmark in a zero-shot setting.

E5 is trained on a large corpus of text and code. This allows it to capture more nuanced semantic relationships than other models. In their first step, the researchers mine the Internet to compile CCPairs (Colossal Clean Text Pairs), a huge, diverse, and high-quality text-pair dataset for training general-purpose text embeddings. They employ a novel consistency-based filtering technique to further improve data quality and end up with 270 million text pairs for contrastive pretraining.
After using contrastive pretraining on the CCPairs, the team fine-tunes the output embeddings and adds human knowledge by training their model on a small, high-quality labeled dataset made up of the NLI 6 Natural Language Inference, MS-MARCO passage ranking, and Natural Questions datasets. This approach is called weakly-supervised training, and it helps E5 learn to distinguish between similar and dissimilar text pairs.
The results of the paper show that E5 is a significant improvement over existing text embedding models. It is especially effective for zero-shot retrieval tasks, where the model is not given any labeled data for the specific task. E5 is a promising new model that has the potential to improve the performance of a wide range of natural language processing tasks.
Hosting an E5
The E5 is such a small model, hosting an E5 is not hard at all. You can even run it on your local machine, with or without a GPU. But to make the process closer to product settings, let us host it on a GCP compute engine instance. For this experiment, I use the GCP n1-standard-4 instance with 4 vCPUs, 15 GB of memory, 30 GB of disk, and a NVIDIA T4 GPU. The T4 GPU has 2560 cores and 16 GB of memory, a lower-end GPU but already enough for this experiment.
When the instance started running, connect to it by SSH and run the following command to install Python and the necessary library:

Then we need to install the NVIDIA CUDA driver. This is a necessary step for the Python library to recognise the GPU resource. Please notice that the following works for my Debian instance, the process may be slightly different for other operating systems:

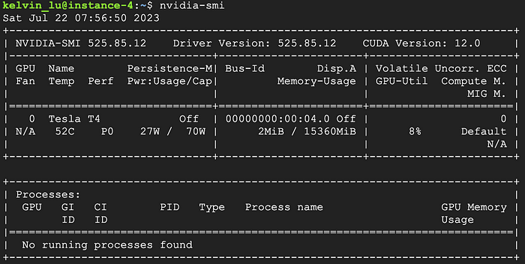
After the installation of the Cuda driver, we can verify the installation by running the nvidia-smi command. If the installation was successful, we should see the following information:
Now, the environment is ready. Let’s write a simple script for testing and name it as e5_large_testing.py:

The first line imports the sentence_transformer, which is a HuggingFace wrapper of a large number of open source models.
The second line specifies the model to use and whether to use cpu or gpu.
The third line defines the payload of the input text. According to the E5 instruction, the string has to start with either ‘query:’ or ‘passage:’. E5 can only process an input length of 512 tokens, which is shorter than the OpenAI embedding model’s context length.
The seventh line loads the model to produce the encoding. The result is a vector of 1024 dimensions.
The script is runnable by:

The sentence_transformer will take several minutes to download and install 2.7 GB of data for the model and the weight files.
Speed Comparison
The result of running a different length of input against the E5 model with GPU or CPU and the OpenAI model is the following:
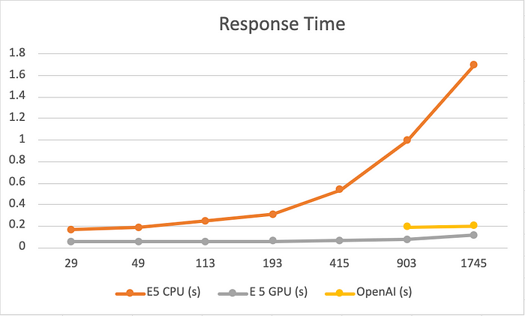
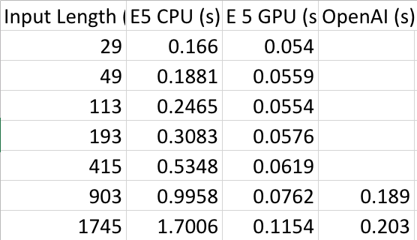
We can see that the GPU has significantly enhanced the model’s performance. And also, the OpenAI embedding model is nearly two times slower than the E5 on GPU performance.
Let’s look at the speed issue from a different angle and imagine we need to process a payload of 100 million tokens. The OpenAI embedding model has the following rate limit:

If we do a simple calculation, we will see that it takes at least 4.76 hours to process the 100 million tokens’ data. If we do the same calculation for the E5 GPU instance, assuming each request has 512 tokens and the process time is 0.12 seconds, we’ll find the same payload will take more than 6.51 hours to process. That looks less impressive compared to the OpenAI throughput; however, bear in mind that the result is based on a low-profile GPU and a single instance. It’s not easy to outperform the OpenAI capacity by either using a more powerful GPU or running a cluster of low-cost instances.
Let’s Talk About The Money
This is the pricing for the compute engine instance:
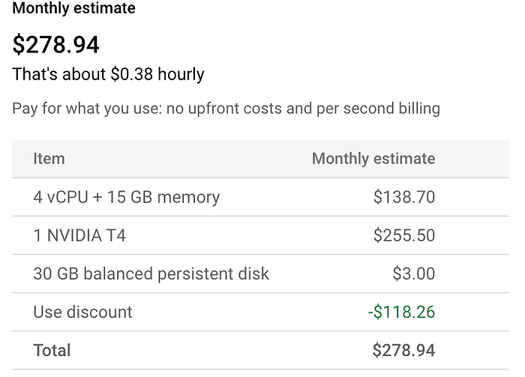
If we use the same instance to process the 100 million token payload, the cost would be $2.47. The same task will cost $10 for the OpenAI model.
The OpenAI embedding model is not fine-tuning!
Actually, not only the OpenAI model is not fine-tunable, Google Vertex AI embedding model doesn’t support fine-tuning either.
For most projects and developers, this is not a big deal as long as the model can provide a decent outcome. But the question is, what if we run into problems caused by incorrect embedding results? In that case, ownership of the solution would be very important.
I’ll experiment with how to fine-tune an embedding model later in the next post.
Conclusion
We have talked about how open-source solutions, like the E5 model that is developed by Microsoft, can help us get better results than commercial embedding models from large companies. In addition to the out-of-the-box performance enhancement, we can also obtain better control of the embedding model. We can fine tune the model to make it more specific to the project’s needs.
In this experiment, many production-oriented aspects have been ignored to make it simple. For example, in a proper enterprise setting, it makes sense to wrap up the embedding model with an API service so that it can be decoupled from its consumer. The service may be better run in an auto scaled cluster of instances to make it robust and scaleable.
References
MTEB: Massive Text Embedding Benchmark
MTEB Leaderboard – a Hugging Face Space by mteb
intfloat/e5-large-v2 · Hugging Face
A Survey of Embedding Models (and why you should look beyond OpenAI)