Why ELT over ETL in the new Compute and Storage Separated Paradigm
| @intelia | August 10

Introduction
In the past, there are a lot of circumstances where Compute and Storage are tightly coupled before they can be separated, for example, HDFS. This will introduce problems when your compute requirement gets more complicated or your data volume increases. Luckily, we are in Cloud Era now, with the help of Cloud, we are gaining huge number of benefits from the Separation of Compute and Storage such as flexible scaling and better resource utilisation. When both Compute and Storage capabilities are ready to serve, it is time for data integration solution to shine, and that would be ELT and ETL from the high level. Let’s take a look at the differences between these 2 approaches from some specific aspects.
Data Lake Compatibility:
- ETL: Not an appropriate way for Data Lake as it transformed data for relational data warehouse purposes.
- ELT: Able to ingest unstructured data.
IMHO: In a lot of real-world cases, enterprises want to keep the original data for some reasons and perform transform to serve analysis as needed.
Data Volume:
- ETL: Suitable for dealing with small datasets.
- ELT: Suitable for large amount of unstructured and structured data.
IMHO: We just simply can’t stop the growth of data volume nowadays, which put a lot of pressure on ETL in terms of processing speed.
Implementation:
- ETL: Existing tools available as well as ETL expert available to help with implementation.
- ELT: Data ecosystem needs to be developed to fit various purpose.
IMHO: building your own data pipeline could be essential because you might have some requirements that exist tool is not capable of doing it, and also third party tool will introduce security risk to big enterprises like banks.
Transformation:
- ETL: Transform happening in a staging area outside data warehouse.
- ELT: Transform happening inside data ecosystem itself and can be performed as needed.
IMHO: usually in ETL, the data is almost immediately available for analysis purpose in the data warehouse, and in ELT the analysis will take a little bit longer if there is not enough processing power. However, processing power is not a problem in cloud nowadays, and there are multiple ways to boost the querying performance.
Load:
- ETL: Data is loaded in a staging area first before loading into data warehouse.
- ELT: Data is loaded directly into target system.
IMHO: ETL could be very time-consuming since the purpose is to transform and load the data into warehouse so that data can be served directly. ELT does not have this problem since it is loading the whole data directly into target system and perform transform later on.
Maintenance:
- ETL: Requires some maintenance.
- ELT: Requires very little maintenance.
IMHO: on-prem ETL solution could address big effort of maintenance. With the help of Cloud and automation solution, both require little maintenance.
Cost & Hardware:
- ETL: ETL: Can be costly.
- ELT: Cost friendly.
IMHO: ELT can load and save data into a storage place with low cost, and perform transform as needed. This reduces money spent in the initial phase as you only load and save data.
Compliance:
- ETL: Suitable for compliances with various standards since sensitive data are masked before loading into target warehouse.
- ELT: Expose risk since all data are loaded into target warehouse.
IMHO: Yes, ELT expose risk of not catering sensitive data in the first place. However, there is Google best-practises for enterprises to adopt in order to take care of data tokenisation within ELT.
Case 2 below will introduce how a large Australian financial institution overcome this defect in production.
Case Study 1: Large Australian Logistics Provider – Teradata Migration Project
From the comparison of ETL and ELT, we can clearly tell that ETL suits a lot of scenarios in the past. However, with Cloud-based solutions getting more mature, ELT methodology is getting a lot of favour due to its flexibility, “moneybility” and so on. Let’s take a look at an example from a large Australian logistics organisation project where ELT is adopted. The organisation is aiming to decommission Teradata Licence, so the team build a data ingestion pipeline to feed the data into BigQuery instead of Teradata database from the source.
The diagram below indicates the design pattern from a high level:
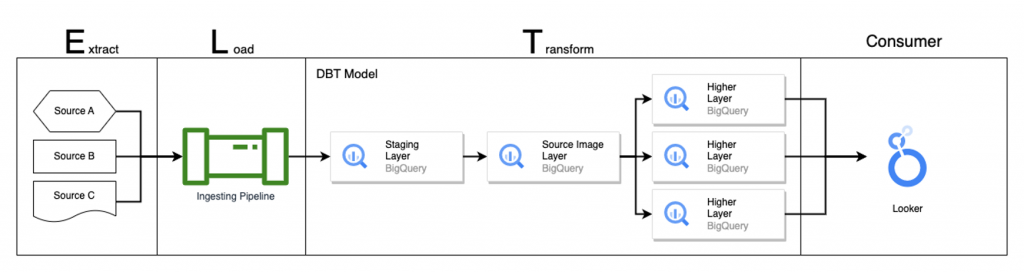
All data sources are now ingested into a Staging Layer in BigQuery directly via a data ingestion pipeline. The Staging Layer datasets will be the starting point for data transformation of upstream layers in other GCP projects. The transform process is executed via DBT models running in Cloud Run and Kubernetes Engine. The upstream layer data will ultimately be consumed by data analytics or visualisation tools like Looker etc.
By implementing this ELT strategy, the organisation have moved towards a better data transformation architect. With ELT, they achieved better performance and cost-effectiveness within GCP data warehousing. The infrastructure design is much simpler with both flexibility and scalability. Batch processing and development time have significantly reduced with fewer errors due to the automation solution implemented in the cloud.
Since all data is loaded first into the GCP data warehousing, developers and consumers also benefit from this ELT strategy. For example, if developers have difficulties in deciding the way of using the data, they can always perform the transform logic in a different schedule; no additional storage servers are needed to be purchased when the amount of data grows due to the scalability in the cloud; data analytics and visualisation become more convenient and powerful under the help of cloud tools.
Case Study 2: Enterprise Global Financial Institution
The organisation, a large Australian financial institution, initiated a project to support a new mobile app feature. They built a data pipeline to ingest data into BigQuery from multiple sources. However, the data contained PII data, and needed to be tokenised.
The diagram below indicates the design pattern from a high level:
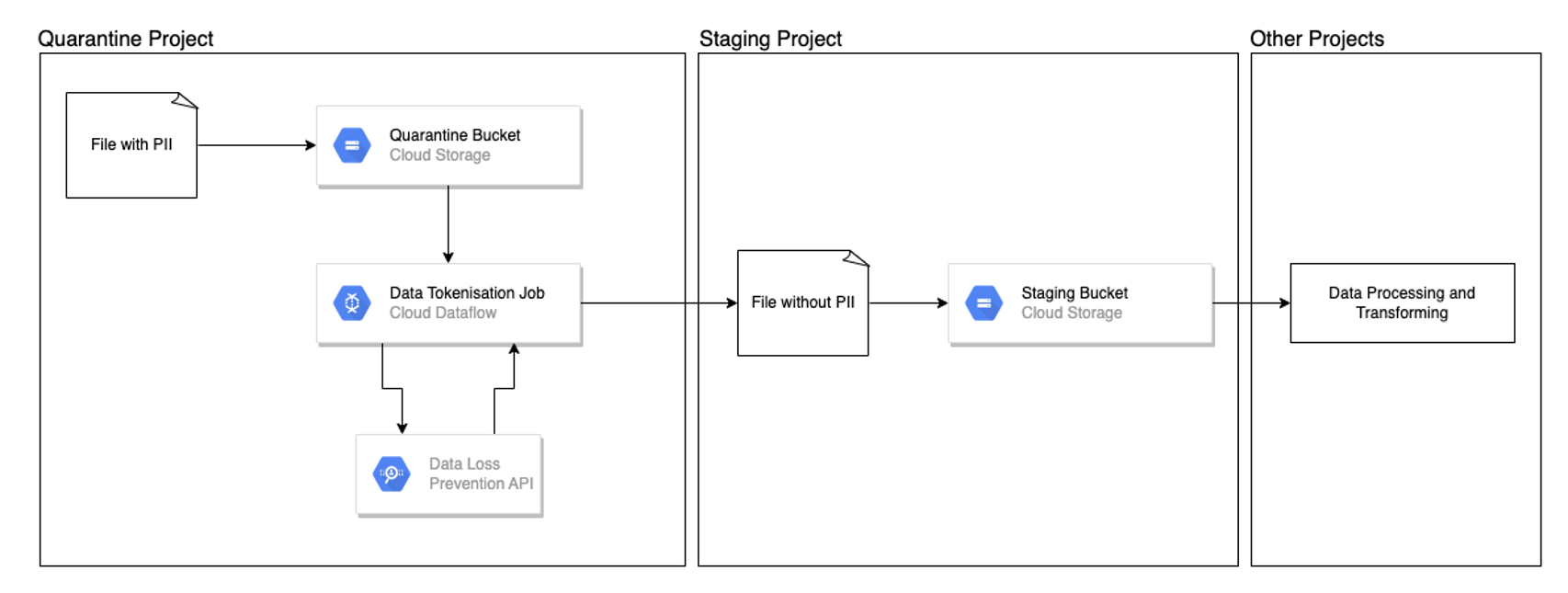
All data will be loaded into a quarantine Google project first with strict IAM policies that block access from any outsiders. Once files land in the Quarantine buckets, the bucket notification will trigger the Cloud Function to kick off a Dataflow Job. The Dataflow Job will call Google DLP API to tokenise sensitive data to a non-reversible value and out the file to a Staging Bucket in other projects for further processing. By implementing this Google Best Practise, the organisation was able to adopt ELT strategy in a secure way without worrying about exposing customers’ sensitive data.