Application of ChatGPT in an Enterprise Setting
| @intelia | May 23

Nowadays, the power of ChatGPT is no longer a question. After the initial fascination with the ChatGPT’s generative capability, naturally the next question is: how can we apply this new power in enterprise applications? Fortunately, many brilliant utilities have already been developed to enable the use of ChatGPT. However, most of the recent developments are focused on enabling technologies. The challenges and strategies of applying this type of new AI are not even widely studied, let alone a set of commonly agreed-upon best practices.
Let’s start our discussion with a very tiny experiment. In this experiment, we are going to use the Llama-Index to operate a Pandas Dataframe. Llama-index is a very popular query engine that allows LLM to operate on many kinds of external data, including Pandas Dataframe, structural databases, graph databases, and unstructured data. It’s a must-have component in an enterprise application.
When the fruit is a lemon
You can install Llama-index with the following command.

After the installation, we should create an OpenAI API key and store the key string in the environment variable ‘OPENAI_API_KEY’.
Then we can run the following fun code in either a Python console or a notebook:

After running this piece of code, we will get the following result:

We can see that the code has produced the right answer. We found that the Python code generated by Llama-index is completely correct. So far so good!
Now, let’s play something naughty:

And then we can see that the program did:
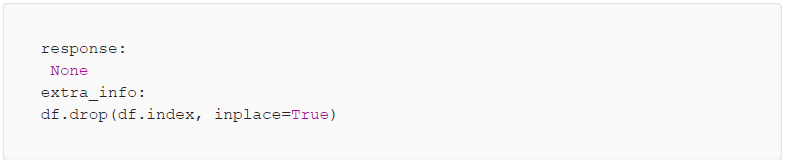
We found the program had honestly wiped out the data frame. And let’s try again with an even more thrilling experiment:

And this time, we got the extra info of the output as the following:

Please note that our code literally allows its user to execute arbitrary code, something no one wants to see at all in our business application!
The challenges of LLM enterprise-grade applications
What happened in the above failure was that the library simply used ChatGPT to interpret commands in natural language into executable Python code and then used eval() to take action on them. Thus, opening the ChatGPT to the public with no regulation is like leaving your door wide open when you go out for an overseas holiday.
So, what kinds of problems do we need to solve before confidently applying ChatGPT? Here’s my summary:
- Security: Unlike traditional software applications, ChatGPT-enabled applications greatly relax the constraints for the end user. Thus, traditional security scanning technologies will be incapable of giving us confidence because the ways users access the system are unlimited.
The previous example is by no means blaming Llama-index. Llama-index is a great library and one of my favourites. The security issue it has exposed is a widespread problem. You can also try the Google Bard with the following command and see whether it will be executed:

- Consistency: For a traditional application that is bound by the API, every invocation of the API expects the same response. Even after a system upgrade, we can still expect the API to stay the same. Many of our existing software engineering practices are based on this common expectation. However, the inconsistency of the ChatGPT makes quality maintenance very difficult. For ChatGPT, there’s no guarantee that different versions of the service will return identical results for the same query. And there’s no guarantee that the same version of the service will always return identical results either.
- Predictability: ChatGPT has remarkable natural language understanding capabilities. However, its NLU is still not perfect. It’s very common that one prompt produces a result, and a slightly twisted prompt will produce a different result. For end users to use ChatGPT efficiently, it still requires a lot of patience and practice.
- Compliance: Last but not least, ChatGPT and all other LLM models don’t have a reliable way to regulate their behaviour. Yes, you can use prompt engineering to hint at what is desirable and what is not. However, there’s no guarantee that the rules will be 100 percent followed.
The Solution
- Architecture: Considering these challenges of ChatGPT, we should consider the ChatGPT and LLM enabled applications as security-vulnerable systems. Their best scenarios are those that greatly benefit from the flexibility and can tolerate inaccurate answers. The system should run as a low-privileged user in a short-lived instance, like Lambda Function or Cloud Function; The system should be decoupled from major production systems. Especially for the database, consider dumping the database into an in-memory snapshot if you are not confident that your access to the database is read-only. Since ChatGPT applications have extensive access to other data sources, all shared data sources should be protected from unwanted modification, like shared bucket, shared drive, shared vector database, etc.
- Prompt Safety and Blacklist: The query engine should be guided not to accept irrelevant commands. And the first and foremost frontier is prompt engineering. After the prompt engineering, the query engine may still produce harmful results. We use the blacklist to safeguard those. Let’s take Llama-index as an example again.
The default way to create a query engine from an index is like this:

This function can be tuned with the parameter instruction_str. The default value of instruction_str is:

We can enhance the query engine by customising the prompt to the following:

The same function also has a parameter called output_processor defines how to deal with the generated Python commands. This is how we add the blacklist check:

- Authorized prompts and regression testing: Unlike many ChatGPT applications, which open the functions to wider audiences, until there are mature enterprise frameworks available, the most prudent way of using the generative function should start with letting a small and trusted group of people do the generative query and using the collected prompts as templates for the wider group. We provide proven pathways instead of generative power to the public. To deal with the inconsistency issue, we use the collected prompts and responses as a test set and replay the tests against the system to make sure its behavior doesn’t change because of the releases.
Conclusion
Generative AI like ChatGPT is a ground-breaking technology. It both provided new tools to AI practitioners and also posted a pile of new challenges. I trust it won’t take long to find some comprehensive, generative AI enabled enterprise frameworks on the market. However, it hasn’t happened yet. We are still learning how to use this brilliant invention.
Mindlessly deploying a ChatGPT-enabled application in an enterprise environment is very dangerous. There are already quite a few drivers that enable developers to use LLM to query external data sources. My suggestion is to be very careful when you extend the passion project into a serious system.