Apache Spark 3.0 — A Next-Generation data processing and analytics workload
| @intelia | January 11

Nearly every organisation worldwide has embarked on creating data storage/lake for meeting enterprise on-demand data needs. Further, transformed and serviced to create robust decision-making systems. The in-memory parallel distributed processing framework has made Apache Spark one of the unified analytics engines in Big Data advanced analytics.
Apache Spark provides APIs in Java, Scala, Python, and R, and an optimised engine for data processing and querying capabilities on data lake using higher-level tools like Spark SQL for SQL and structured data processing, MLlib for machine learning, GraphX for graph processing, and Structured Streaming for incremental computation and stream processing.
Since the initial release in 2010, Spark has come a long way and has grown to be one of the most active open-source projects. In the TPC-DS 30TB benchmark, Spark 3.0 is roughly two times faster than Spark 2.4 enabled by adaptive query execution, dynamic partition pruning, and other optimisations.
From the high volume data processing perspective, I thought it’s best to put down a comparison between Data warehouse, traditional M/R Hadoop, and Apache Spark engine.

In a traditional Data warehouse, fast SQL queries, data model, and data catalogs are the main feature required to access data reliably and faster. However, older big data and Hadoop versions did miss on these critical features like SQL optimisation and data catalogs. Additionally, it became challenging to implement data governance across these vast data lakes. Apache Spark has provided a platform for data engineers to run massive ETL workloads and data analysts and scientists to collaborate under a single roof, thus making data processing and consumption faster and smarter.
Complete list of Apache Spark 3.0 features

The key features in Apache Spark 3.0 :
1. Delta Lake
2. Improved SQL Optimisation and Data Catalog
3. Koalas: Pandas API on Spark
4. Kubernetes as Resource Manager
Delta Lake
The biggest shortcoming in Hadoop systems was the ACID transactions. Typically when data is sourced into the data store one needs to manipulate and transform data without losing data integrity. Delta Lake brings that kind of reliability to data lakes. Delta Lake provides ACID transactions, scalable metadata handling, and unifies streaming and batch data processing. Delta Lake runs on top of your existing data lake and is fully compatible with Apache Spark APIs.
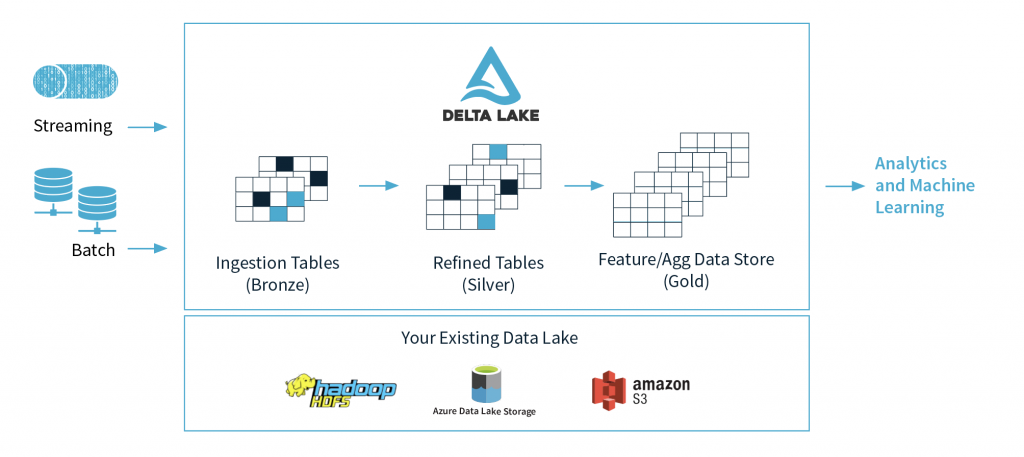
Main features of Delta Lake
ACID transactions — Provides serializability isolation level to ensure data integrity and concurrency.
![]()
Schema enforcement — Delta Lake provides the ability to specify your schema and enforce it to ensure the data types are correct and required columns are present, preventing bad data from causing data corruption.

Scalable metadata — Delta Lake treats metadata just like data, leveraging Spark’s distributed processing power to handle all its metadata. That means you can access and query petabyte-scale tables with billion partitions and files,
Time Travel — Delta Lake provides a snapshot for data version to help developers and admin to access and revert to the previous version for managing audit and rollback requirements.

Updates and Deletes — Delta Lake supports API to perform the merge, update, and delete functionality on datasets.

With the integration of Data Lake, ACID capabilities have become easier and quicker to manage data attributes using proper isolation level and data manipulation functionality.
Improved SQL Optimisation and Data Catalog
Few improvements for the DataSource API are included with Spark 3.0:
Pluggable Data Catalog (Datasource V2) — Integrated catalog provides functionality to plug in any kind of data sources into data catalog.
Improved pushdown — Improved predicate push down for faster queries via reduced data loading
Unified APIs for streaming and batch
Example
df.writeTo(“catalog.db.table”).overwrite($”year”===”2019)
Adaptive Query Execution
Provides better optimization plans during query execution bases on the size of the tables and join conditions. Performs dynamic shuffle partitions, switches join strategies, e.g. “merge join” to “broadcast join”, and optimises skew joins.
Additionally, developers can now analyse the cached table to optimise the query execution plan.
Dynamic Partition Pruning
Speeds up expensive joins based on the time taken to identify partitions it can skip. A very common technique applied in the data warehousing world where the fact table joined to the dimension table can prune partition by identifying the partitions that result from filtering the dimension table. In a TPC-DS benchmark, 60 out of 102 queries show a significant speedup between 2x and 18x.
Koalas: Pandas API on Apache Spark
A big add-on for Python developers, especially data engineers and scientists is performance. Koalas API can enable compute to efficiently scale out to hundreds of worker nodes for everyday data science and machine learning needs. A developer/Scientist with Pandas background can now scale up from a single-node environment to a distributed environment without understanding the nuances of Spark Dataframes separately.
Koalas uses PySpark DataFrame internally and externally it works as if it is a pandas DataFrame. Hence migration of Panda code into Apache Spark is now easy and manageable.
Example
Pandas:
import pandas as pd
df = pd.DataFrame({‘x’: [1, 2], ‘y’: [3, 4], ‘z’: [5, 6]})
# Rename columns
df.columns = [‘x’, ‘y’, ‘z1’]
# Do some operations in place
df[‘x2’] = df.x * df.x
Koalas:
import databricks.koalas as ks
df = ks.DataFrame({‘x’: [1, 2], ‘y’: [3, 4], ‘z’: [5, 6]})
# Rename columns
df.columns = [‘x’, ‘y’, ‘z1’]
# Do some operations in place
df[‘x2’] = df.x * df.x
Kubernetes as Resource Manager
- Apache Spark 3.0 introduces a new shuffle service for Spark on Kubernetes that will allow dynamic scale up and down making scheduling more flexible and efficient with GPU and pod level isolation for executors.
- Extention and support of the Apache Spark pods to execute on Kubernetes
- Supports Kerberos authentication in the cluster and client mode.
- Can request a specific number of cores for the driver with the help of Spark.kubernetes.driver.request.cores property.
The Kubernetes scheduler is currently experimental. In future versions, there may be behavioural changes around configuration, container images and entrypoints.
References
https://databricks.com/blog/2020/06/18/introducing-apache-spark-3-0-now-available-in-databricks-runtime-7-0.html
https://delta.io/
https://spark.apache.org/releases/spark-release-3-0-0.html
https://koalas.readthedocs.io/en/latest/
http://spark.apache.org/docs/latest/running-on-kubernetes.html#resource-allocation-and-configuration-overview
https://docs.databricks.com/delta/optimizations/delta-cache.html
https://docs.microsoft.com/en-us/azure/databricks/delta/
https://databricks.com/blog/2019/02/04/introducing-delta-time-travel-for-large-scale-data-lakes.html