Time To Take Insights from Raw Data
How We Speed Up the Process

-
- Disparate data sources
-
- Data Analysis is time consuming and cumbersome

-
- Accelerated time to insight
-
- Autonomous data engineering
-
- Alleviate complex and time-consuming data movement and transformation
Challenges
Disparate data sources are being used by organisations to consume insightful data and information. The data sources can be relational, file based, API based, or Application based. With this type of coverage, gathering live data from multiple sources across the organization can be a long, manual process. Additionally, it’s imperative for organisations to analyse the data in a timely manner as data can become “stale” quickly. Most organizations face a huge challenge when the most valuable data sources can be difficult and time consuming to analyse in order to make better decisions, reduce costs and improve time to value.
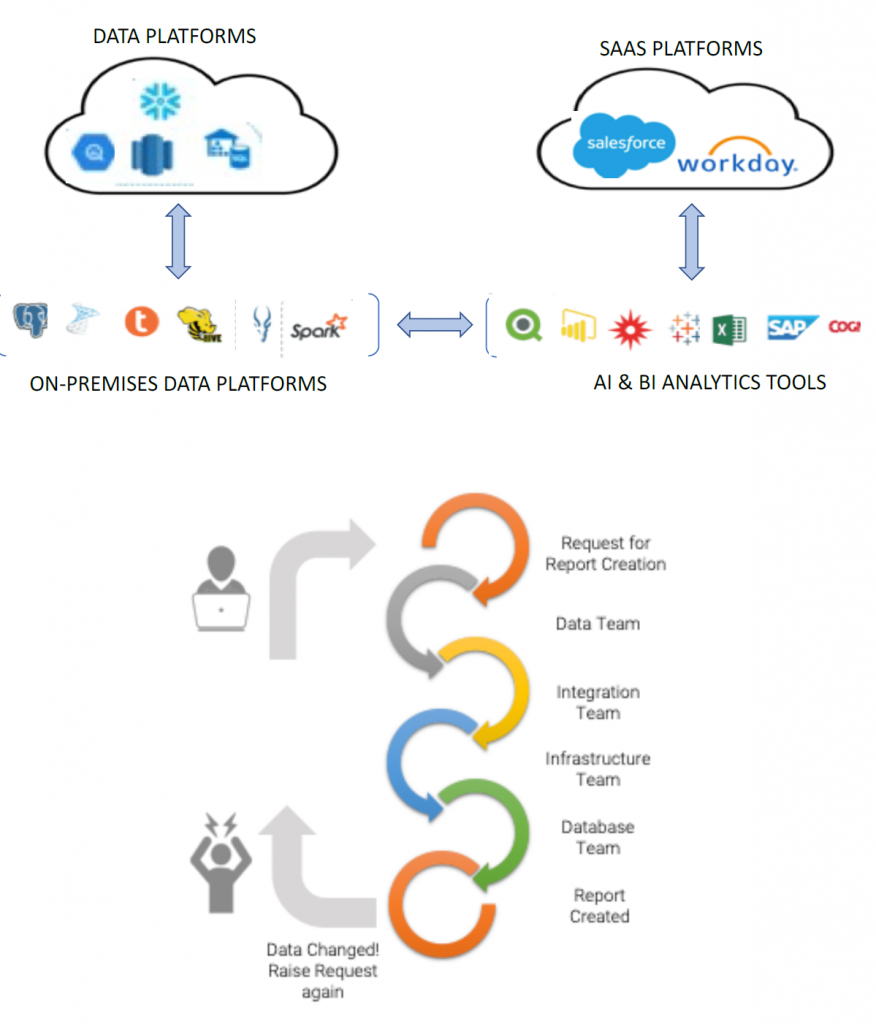
Solution
Rapid time to insight is one of the biggest competitive edges an enterprise can have today. An accelerated time to insights allows businesses to make better decision based on accurate information, reach business goals, and think bigger. This can be achieved by eliminating repetitive data engineering tasks like curating, maintaining, and delivering data for analysis. Automating data engineering practices will enable identifying these shortcomings and applies multiple strategies for resolution. An ideal tool will learn from user behaviour and data relationships to improve data agility, security, and performance. Data insights can be significantly improved by managing the ever-changing data and eliminating manual process to absorb data changes into the data model.
How AtScale can help
AtScale organises information coming from disparate data sources into a single view to help make better decisions, reduce costs, and improve time-to-value. AtScale provides autonomous data engineering, which alleviates complex and time-consuming data movement and transformations, and adds additional security and governance for true self-service analytics – no matter where the data is stored or how it’s formatted.
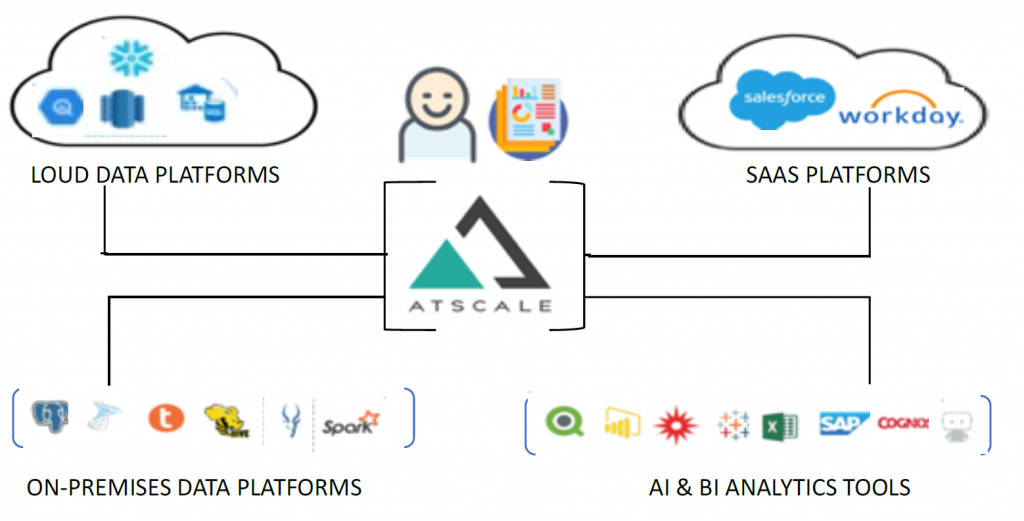
AtScale implements “no data movement” architecture i.e., as soon as data lands in a Distributed File System (for e.g.: HDFS), it’s immediately available to users with no prior extraction or transformation. It is purely a schema on-read architecture, where the cube definition itself contains the transformations. Transformations are injected at runtime when the queries are executed. Cubes can be thought of as a semantic business layer on top of HDFS, contained within Hadoop.
This seamless architecture makes the best use of both Hadoop and BI tools, without the need for additional client software and drivers. Employing an intelligent data fabric layers AtScale minimizes business interruption when enterprises move data between backend warehouses. Since intelligent data fabrics contain a business-centric data model, they can be repointed to wherever data is moved to.